Damit die künstliche Intelligenz von ChatGPT gute Texte schreiben kann, wird sie überwiegend mit Inhalten aus dem Internet trainiert. Darunter auch urheberrechtlich geschütztes Material. Autoren und Verlage, die künftig verhindert wollen, dass die KI von eigenen Texten lernt, können jetzt ChatGPT von der eigenen Website aussperren.
Künftig gibt sich ChatGPT zu erkennen, wenn sich das »Texternteprogramm« des Herstellers OpenAI die Inhalte der eigenen Website einverleiben will.
Es ist eine Kennung, wie sie jeder Browser und beispielsweise auch Google verwendet, wenn Inhalte ausgelesen werden. Der sogenannte Bot von OpenAI identifiziert sich mit der Kennung »GPTBot«.
Wer nicht möchte, dass die Texte der eigenen Website zum Training der Text-KI verwendet werden und dass sich ChatGPT beispielsweise auch an Leseproben oder kostenfrei bereitgestellten und urheberrechtlich geschützten Inhalten bedient, kann den Bot mit einer sogenannten robots.txt-Datei von der kompletten Website oder Teilen davon ausgeschlossen werden. Auch diese Technik ist nicht neu, sondern kann seit jeher genutzt werden, um maschinelle Besucher wie z. B. Google von der Indexierung auszuschließen.
Um die komplette Website für den GPTBot zu sperren, legt man im Hauptverzeichnis des Webservers eine Textdatei mit dem Namen robots.txt ab. In diese Datei schreibt oder ergänzt man die folgenden Zeilen:
User-agent: GPTBot Disallow: /
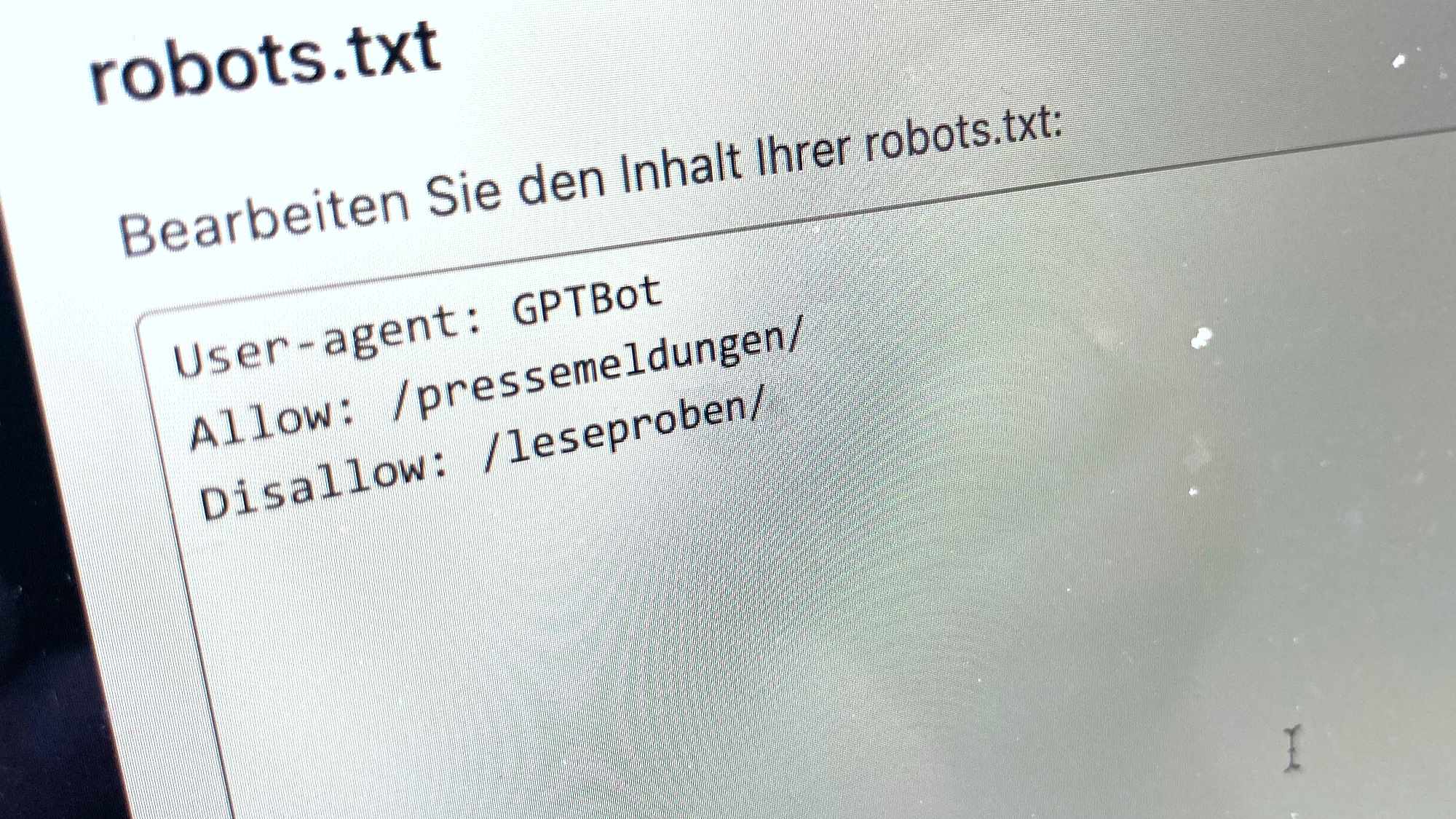
Man kann dieses Kommando auch verfeinern, indem man dem Bot gezielt den Zugriff auf echte oder virtuelle Unterverzeichnisse entzieht oder erlaubt:
User-agent: GPTBot Allow: /pressemeldungen/ Disallow: /leseproben/
Für Content-Management-Systeme wie WordPress gibt es Erweiterungen (Plugins), mit denen sich die Datei robots.txt editieren lässt. Das oft eingesetzte SEO-Plugin von Yoast ermöglicht die Bearbeitung unter »Yoast SEO > Werkzeuge > Datei-Editor > robots.txt«
Natürlich ist man bei der ganzen Sache darauf angewiesen, dass sich ChatGPT bzw. OpenAi auch an diese Anweisungen hält. Und natürlich kann man sich auch fragen, warum man aktiv etwas tun muss, um den Bot auszuschließen. Aber das kann man leider nicht aussuchen. Außerdem gibt es mittlerweile zahlreiche ähnliche KI-Anbieter, die diese virtuelle Sperre nicht beachten werden.
Von Urheberinnen und Urhebern wird jedoch immer wieder beklagt, dass sich ChatGPT an rechtlich geschützten Inhalten bediene, ohne dass die Urheber dafür entlohnt werden. ChatGPT lernt ungefragt von den Texten anderer, ohne Schulgeld zu bezahlen. Dass sich der Bot von OpenAI nun zu erkennen gibt, mag ein kleines Zugeständnis nach dieser Kritik sein.
Wer seine Inhalte also vor dem Zugriff schützen möchte, sollte die erwähnten Zeilen in seine robots.txt-Datei einfügen.
Danke für den Tipp.
Sehr guter Hinweis.
Es kann nicht sein, dass die Tech-Firmen mit der geistigen Arbeit anderer steinreich werden.
Ich werde den Hinweis umsetzen.
Ja, das sollte eigentlich jeder machen.
Ohne massenhaften Input ist die KI nämlich nutzlos.
Es wirkt sich nur leider nicht auf bereits gecrawlte Inhalte oder andere Trainingssets aus. Google will seine Infos aus den Suchcrawls 1:1 für Bard verwenden, ohne Wahlmöglichkeit.
Bessere Ansätze sind die TDM Directive der EU (IMHO wahrscheinlich zahnlos) und die TDMrep-Erweiterung aus dem W3C-Umfeld (zu unkonkret und unflexibel, wird sich so nicht durchsetzen). Ein paar Sätze mehr dazu hier (Englisch): https://netfuture.ch/2023/07/blocking-ai-crawlers-robots-txt-chatgpt/
Danke für die Information.
Guter Tipp, danke Dir!